函数 && 文件存储 && 异常
1.如何给函数写注释
1 | def a(name): |
2.关键字参数
1 | def a(name,words): |
使用关键字参数,可以有效避免因不小心搞乱参数的顺序导致的BUG出现
3.python的return语句可以返回多个不同类型的值吗?
可以,默认用逗号隔开,以元组的方式返回,也可以用列表的方式返回
def myFun():
return ‘你’, 520, 3.14, True
myFun()
(‘你’, 520, 3.14, True)
def myFun2():
return [‘我’, 1314, 5.12, False]
myFun2()
[‘我’, 1314, 5.12, False]
4.全局变量global的使用
1 | x = 10 # 全局变量 |
输出结果:函数内部 x = 20 函数外部 x = 10
1 | x = 10 # 全局变量 |
输出结果:函数内部 x = 20 函数外部 x = 20
5.在嵌套函数中,如果希望在内部修改外部函数的局部变量,用什么关键字?
nonlocal
def Fun1():
x = 5
def Fun2():
nonlocal x
x *= x
return x
return Fun2()
Fun1()
25
6.如何利用函数闭包写一个计时器函数
1 | import time |
开始运行程序
Hello World!
程序运行时间为2.00秒
7.如何不显式调用time_master()来实现一样的功能呢?
装饰器
1 | import time |
这里装饰器的实质其实是
1 | myfunc = time_master(myfunc) |
8.装饰器可以嵌套使用吗?
1 | def add(func): |
输出结果:65
9.map函数和lambda表达式
可以将一个函数应用于一个或多个可迭代对象(如列表元组)的每个元素,并返回一个迭代器
1 | map(function,iterable.……) |
function:要应用的函数
iterable :一个或多个可迭代对象
1 | *# 将列表中的每个数字平方* |
1 | # 将两个列表的对应元素相加 |
还可以与内置函数结合使用
1 | # 计算列表中每个字符串的长度 |
10. 请使用lambda表达式将下边函数转变为匿名函数?
1 | def fun_A(x, y=3): |
1 | lambda x,y=3 : x*y |
11. 你可以利用filter()和lambda表达式快速求出100以内所有3的倍数吗?
1 | list(filter(lambda n : not(n%3), range(1, 100))) |
12. 还记得列表推导式吗?完全可以使用列表推导式代替filter()和lambda组合,你可以做到吗?
例如将第3题转为列表推导式即:
1 | [ i for i in range(1, 100) if not(i%3)] |
13.还记得zip吗?使用zip会将两数以元祖的形式绑定在一块,例如:
2
[(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]但如果我希望打包的形式是灵活多变的列表而不是元祖(希望是[[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]这种形式),你能做到吗?(采用map和lambda表达式)
2
[[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]注意:强大的map()后边是可以接受多个序列作为参数的
14.生成器 yield
逐步产生值而不是一次性返回所有结果。当调用生成器函数时,它不会立即执行,而是返回一个生成器对象,这个对象可以迭代
1 | #创建生成器函数 |
15.如何用生成器生成斐波那契数列
1 | def fiber(): |
16.生成器表达式
类似于列表推导式,但使用圆括号并返回生成器:
1 | # 列表推导式 - 立即计算 |
17.用迭代和递归的方式分别实现求一个数的阶乘
1 | def gui(i): |
18.用递归求斐波那契
1 | def gui(i): |
19.用递归实现汉诺塔
1 | def hanoi(n,x,y,z): |
20.函数文档以及内省展示
1 | def exchange(dollars,rate=6.5): |
打印“功能:汇率转换,美元->人民币
参数:
- dollars: 美元数
- rate: 汇率,默认6.5
返回值:人民币数”
21.类型注释
1 | def times(s:str,n:int)->str: |
表示希望传入的s,n分别是字符串类型和Int型,并告诉你返回的是str
但这不是给编译器读的,是方便开发者记住的,不用严格按照期望传参
22.什么是高阶函数
- 接受一个或多个函数作为参数
- 将一个函数作为返回值返回
简单来说,高阶函数就是“操作其他函数”的函数。这使得代码更加抽象、灵活和可复用。
23.高阶函数有哪些,它们有什么作用?
Python 在 functools和内置命名空间中提供了几个非常实用的高阶函数,其中最著名的是 map(), filter(), 和 reduce()。
1. map(function, iterable, …)
map()函数会将一个函数映射应用到可迭代对象(如列表、元组)的每一个元素上,并返回一个迭代器(在 Python 2 中返回列表,Python 3 中返回更高效的 map对象,通常需要转换成列表)。
作用:对可迭代对象中的每个元素进行某种转换。
语法:
map(function, iterable)定义一个平方函数 def square(x): return x ** 2 numbers = [1, 2, 3, 4, 5] # 使用 map squared_numbers = map(square, numbers) print(list(squared_numbers)) # 输出: [1, 4, 9, 16, 25] # 更常见的做法是使用 lambda 匿名函数,使代码更简洁 list1 = map(lambda x: x**2, numbers) print(list(list1)) # 输出: [1, 4, 9, 16, 25]**3. functools.reduce(function, iterable[, initializer])** `reduce()`函数在 `functools`模块中,需要先导入。它会对序列中的元素进行**累积**操作。它接收一个二元函数(有两个参数的函数)、一个可迭代对象和一个可选的初始值。它会用这个二元函数从左到右依次对序列中的元素进行累积计算,最终将序列“缩减”为一个单一的返回值。 - **作用**:对序列中的元素进行累积运算。 - **语法**:`reduce(function, iterable[, initializer])` - **计算过程**: `reduce(f, [a, b, c, d])`等价于 `f(f(f(a, b), c), d)`。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
**2. filter(function, iterable)**
`filter()`函数用于**过滤**序列,根据一个返回布尔值(`True`或 `False`)的函数来筛选可迭代对象中满足条件(使函数返回 `True`)的元素,同样返回一个迭代器。
- **作用**:从可迭代对象中筛选出符合条件的元素。
- **语法**:`filter(function, iterable)`
```py
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 定义一个判断偶数的函数
def is_even(x):
return x % 2 == 0
# 使用 filter
even_numbers = filter(is_even, numbers)
print(list(even_numbers)) # 输出: [2, 4, 6, 8, 10]
# 使用 lambda 函数
even_numbers_lambda = filter(lambda x: x % 2 == 0, numbers)
print(list(even_numbers_lambda)) # 输出: [2, 4, 6, 8, 10]1
2
3
4
5
6
7
8
9#计算阶乘
import functools
def jiec(x,y):
return x*y
num=[1,2,3,4]
res=reduce(jiec,num)
print(res)#输出24
24.wraps装饰器的作用
在讲解装饰器时,用到了以下代码
1 | import time |
1 | import time |
此时再打印,就是func了
25.文件操作有哪些方法
1.open方法
Python open() 方法用于打开一个文件,并返回文件对象。
在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
**注意:**使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
1 | open(file, mode='r') |
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
open是传统方法,我们更推荐使用with
26.什么是with语句
with语句是 Python 中用于资源管理的上下文管理协议实现,特别适合文件操作等需要明确释放资源的场景。
文件操作场景
1 | # 传统方式(不推荐) |
数据库连接场景
1 | import sqlite3 |
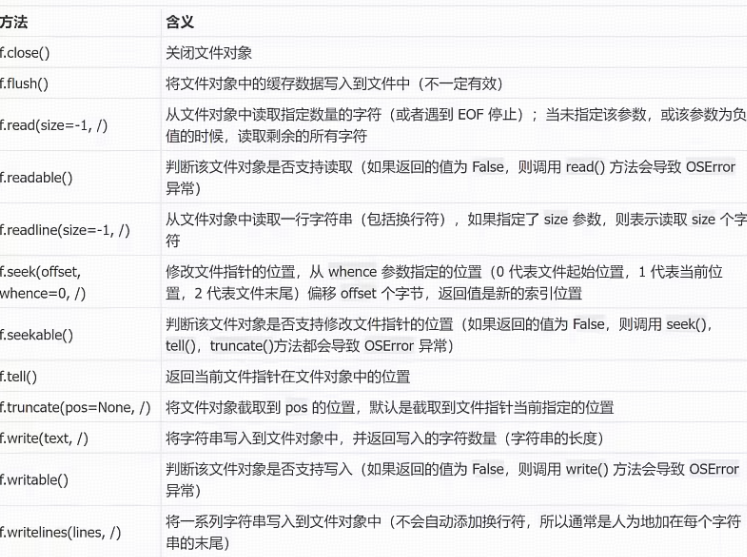
27.Pashlib中path的使用(旧版本使用os.path)
1.创建
1 | from pathlib import Path |
输出结果 D:\python\1.py
D:\python\123
注意斜杠和反斜杠
2.cwd()获取当前路径
1 | path=Path.cwd() |
D:\python
3.Path.stat获取当前文件信息
1 | p=Path('1.py') |
1 | jos.stat_result(st_mode=33206, st_ino=8444249301448143, st_dev=2561774433, st_nlink=1, st_uid=0, st_gid=0, st_size=4, st_atime=1525926554, st_mtime=1525926554, st_ctime=1525926554) |
4.Path.exists判断当前路径是否是文件或文件夹
1 | Path('.').exists() |
5.Path.is_dir()判断该路径是否是文件夹,Path.is_file()判断该路径是否是文件
1 | print('p1:') |
1 | p1: |
6.Path.iterdir()
当path为文件夹时,通过yield产生path文件夹下的所有文件、文件夹路径的迭代器
1 | p = Path.cwd() |
1 | D:\python\1.py |
7.Path.rename(target)
当targrt是string时,重命名文件或文件夹
当target是path时,重命名并移动文件或文件夹
1 | p1 = Path('1.py') |
12.Path.replace(target)
重命名当前文件或文件夹,如果target所指示的文件或文件夹已存在,则覆盖原文件
13.Path.parent(),Path.parents()
parent获取path的上级路径,parents获取path的所有上级路径
14.Path.is_absolute()
判断path是否是绝对路径
15.Path.match(pattern)
判断path是否满足pattern
16.Path.rmdir()
当path为空文件夹的时候,删除该文件夹
17.Path.name
获取path文件名
18.Path.suffix
获取path文件后缀
28.Pickle模块
将Python对象序列化(二进制)
使用dump和
1 | import pickle |
29.异常(Exception)
在python中如果你违背了python的语法规则或者其他原因,就会出现异常,此时编译器会给你红色报错
例如
如果你计算 1/0 ,我们知道0不能被除,那么就会抛出ZeroDivisionerror异常
如果你用字符串和数字相加,就会抛出TypeError异常
那么有没有什么办法让我们可以提前避免报错发现异常并修正呢
try except语句
1 | try: |
当然,如果错误类型不匹配的话,是无法匹配的,也就是说如果你把上面的换成ZeroDivisionError
仍然会报错。
你也可以同时捕获多种异常,比如except(ZeroDivisionerror,TypeError)
你也可以不选择具体类型的异常
try except else finally
1 | try: |
raise
1 | # 主动抛出异常 |
assert
1 | # 断言条件为真,否则抛出 AssertionError |