numpy入门
本文主要参考菜鸟教程和b站莫烦老师的视频,学习过程中发现其实很多部分讲的过于笼统,内容学习顺序不太妥当,有些内容无法直接理解。故自己调整了下学习顺序,对一些内容进行了扩展补充,对一些内容则进行了删改(非常少,基本都涵盖了)。如果你也刚入门,可以看看这篇文章,但是如果你已经是大牛,便不用浪费时间了
1.什么是numpy?
NumPy(Numerical Python)是Python语言的一个扩展程序库,支持大量的维度数组和矩阵运算。也针对数组运算提供大量的数学函数库。
它的运行速度非常快,主要用于数组计算,包含:
- 强大的N维数组对象 ndarray
- 广播函数功能
- 整合c/c++/Fortran代码的工具
- 线性代数,傅里叶变换,随机数生成等功能
(NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用, 这种组合广泛用于替代 MatLab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科学或者机器学习。)
2.如何安装numpy?
前人所述备矣~依旧搬运
3.矩阵的实现(array)
通过array()我们可以实现矩阵的创建,我们需要在括号中填入列表形式的参数。
1 | import numpy as np |
它和列表的一个差别是,没有逗号(似乎显而易见)
而当我们尝试去输出数据类型,会发现一个陌生的字符串“numpy.ndarray”
什么是ndarray?
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要”跨过”的字节数。
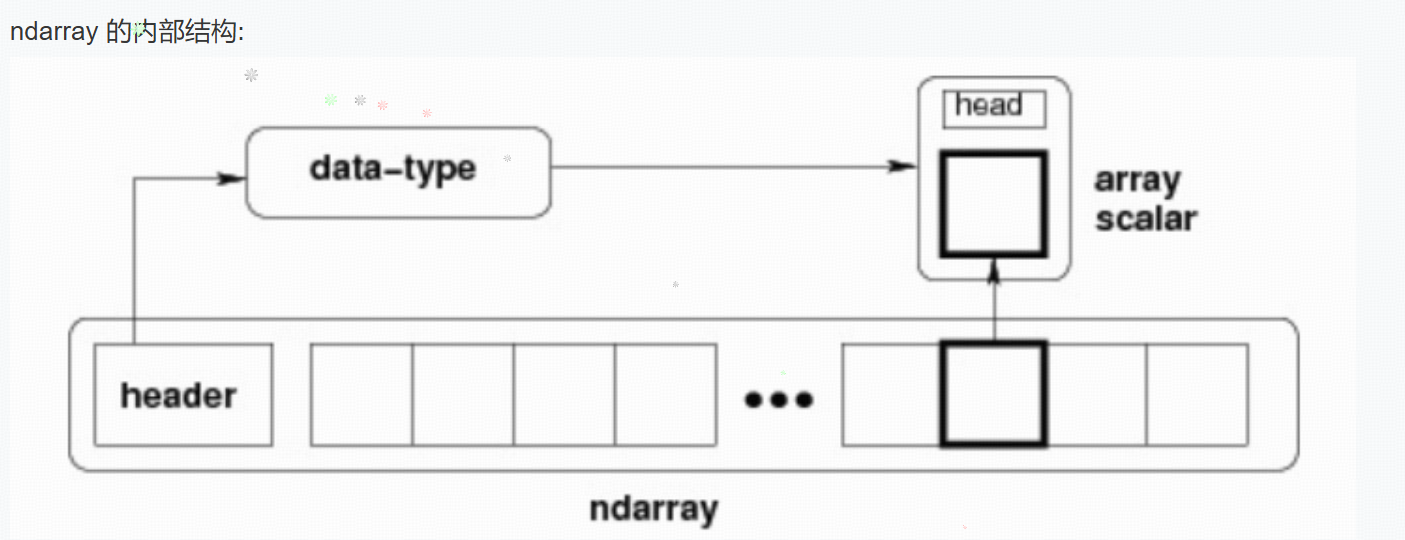
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
1 | numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0) |
这些参数中只有object是必须传入的。下附参数说明:
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
下面我们来实际演示这些参数(只演示比较重要的,如果你感兴趣可以自己搜索)。
一开始我们就演示了一维数组的创立,二维也是同理
1 | # 多于一个维度 |
ndmin(最小维度)
什么是最小维度?顾名思义就是你定义的这个矩阵最少是几维,那你可能会疑惑,要是我定义一个一维数组但是令ndmin=2会怎么样呢?
1 | # 最小维度 |
可以观察到这是有两对[]的。这就是ndmin=2起到的效果。也就是说你改成三的话会有三对[],少于三对会帮你自动补全[],那如果多于三对呢?
答案是什么都不会发生,因为一开始我们就说了这是最少。所以你维度再多也没关系。
detype(数据类型)
1 | import numpy as np |
代码可以看到我们传给dtype的参数是complex,结合输出我们可以看出这是复数的意思。那么numpy有哪些数据类型呢?numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。下表列举了常用 NumPy 基本类型。(看看就行不用硬背)
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
我们用实例来理解一下
1 | import numpy as np |
注意,# int8, int16, int32, int64 四种数据类型可以使用字符串 ‘i1’, ‘i2’,’i4’,’i8’ 代替,所以你看到这些参数不要疑惑,这只是它们的另一种表达方式
1 | import numpy as np |
dtype创建结构化数据类型
NumPy的结构化数据类型(dtype)让你能在数组中处理像数据库表记录或C语言结构体这样的复合数据
创建结构化数据类型我们有四种方式
- 元组列表(最常用最推荐,其他的了解即可)
- 逗号分隔字符串
- 字段参数字典
- 字段名称字典
| 方法 | 语法示例 | 特点说明 |
|---|---|---|
| 元组列表 | dtype = np.dtype([('name', 'U10'), ('age', 'i4'), ('weight', 'f4')]) |
最常用且灵活的方式,直接指定字段名和数据类型。字段名若为空字符串 '',会自动生成 f0, f1等默认名称。 |
| 逗号分隔字符串 | dtype = np.dtype('i8, f4, S3')或 dtype = np.dtype('3int8, float32, (2,3)float64') |
写法简洁,适合快速定义。字段名默认为 f0, f1…。字符串中的数字可以定义数组形状,如(2,3)float64表示一个2x3的浮点数子数组。 |
| 字段参数字典 | dtype = np.dtype({'names': ['col1', 'col2'], 'formats': ['i4', 'f4']}) |
提供高级控制,可精确指定字节偏移量(offsets)、总字节大小(itemsize)等内存布局细节。 |
| 字段名称字典 | dtype = np.dtype({'col1': ('i1', 0), 'col2': ('f4', 1)}) |
不推荐使用,因为在Python 3.6之前字典不保留字段顺序。 |
我们来实例演示一下
1 | import numpy as np |
[('age', np.int8)]是一个列表,其中包含一个元组,这个元组定义了一个字段。'age'是字段的名称,以后可以通过这个名字来访问数组中的这一”列”数据np.int8指定了这个字段的数据类型是8位整数(范围从-128到127),非常节省内存
(是不是觉得和c的结构体非常相似呢)
我们再来看一个例子,下面的示例定义一个结构化数据类型 student,包含字符串字段 name,整数字段 age,及浮点字段 marks,并将这个 dtype 应用到 ndarray 对象。
1 | import numpy as np |
可以看到abc的前面多了一个b,50的后面多了一个‘.’,这就是数据结构化的表现。
这个“.”我们可以理解,浮点数嘛,但是这个b怎么理解呢?
在Python 3中,'abc'这样的文本默认是Unicode字符串(str类型)。而字节串(bytes类型)用于表示原始的二进制数据或经过编码的文本(如UTF-8编码)。当NumPy使用 'S'类型(比如实例中的“s20”)时,它会将你提供的字符串转换为字节串进行存储。打印时,Python为了明确显示这是字节串而非普通字符串,就加上了 b前缀。附表供参考,依旧了解即可不需要背
| 字符 | 对应类型 |
|---|---|
| b | 布尔型 |
| i | (有符号) 整型 |
| u | 无符号整型 integer |
| f | 浮点型 |
| c | 复数浮点型 |
| m | timedelta(时间间隔) |
| M | datetime(日期时间) |
| O | (Python) 对象 |
| S, a | (byte-)字符串 |
| U | Unicode |
| V | 原始数据 (void) |
np.arange
np.arange是 NumPy 中用于创建等差数列数组的重要函数。(可以设置dtype,不做演示)
1 | import numpy as np |
你只传入一个参数时,NumPy会将其视为 stop,序列从 0开始,以 1为步长增长,直到小于这个值。
传入两个参数时,则是start和stop,步长默认1
传入三个参数时,指定 start, stop和 step:这是最灵活的方式,可以完全控制序列。
⚠️ 重要注意事项与替代方案
浮点精度问题:因为浮点数在计算机中表示不精确,使用浮点步长可能到不了预期的stop值。
这时候可以使用
np.linspace()(尤其适用于绘图和数值计算,默认包含重点)
1 | import numpy as np |
- 当
step为负数时,start应大于stop,否则将得到空数组
1 | import numpy as np |
- 步长step不可为0,否则数组会无限长,抛出
ValueError错误
ndarray对象属性
ndarray.ndim 用于获取数组的维度数量(即数组的轴数)。
1 | import numpy as np |
ndarray.shape 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim 属性(秩)。比如,一个二维数组,其维度表示”行数”和”列数”。
ndarray.shape 也可以用于调整数组大小。
1 | import numpy as np |
ndarray.itemsize 以字节的形式返回数组中每一个元素的大小。
例如,一个元素类型为 float64 的数组 itemsize 属性值为 8(float64 占用 64 个 bits,每个字节长度为 8,所以 64/8,占用 8 个字节),又如,一个元素类型为 complex32 的数组 item 属性为 4(32/8)。
1 | import numpy as np |
创建数组的其他方式
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
1 | numpy.empty(shape, dtype = float, order = 'C') |
参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 有”C”和”F”两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
下面是一个创建空数组的实例:
1 | import numpy as np |
输出结果为:
1 | [[ 6917529027641081856 5764616291768666155] |
注意 − 数组元素为随机值,因为它们未初始化。
“垃圾值”的来源:
np.empty为了追求极致的速度,在分配数组内存后,并不会用零或其他特定值去覆盖这块内存区域。这意味着你看到的是这块内存之前被使用后留下的“残影”或任意数据。因此,每次运行程序,或者在不同的计算机上运行,得到的结果很可能都不一样
。
为何有时显示为零:你可能会在某些情况下看到输出结果全是零。这并不代表数组被初始化了。这通常是因为操作系统在分配新内存页时,出于安全考虑会将其清零;或者NumPy恰好复用了一块之前已经被清零的内存区域
。这是一个巧合,并非函数保证的行为。
性能与安全的权衡:
np.empty的设计初衷就是高性能。在你需要创建一个大型数组,并计划立刻用你自己的数据完全填充它时(例如,通过一个计算过程),使用
np.empty可以节省掉初始化为零的开销。但你必须牢记,在手动填充之前,数组内的值是无效且不可依赖的。
2.numpy.zeros
创建指定大小的数组,数组元素以 0 来填充:
1 | numpy.zeros(shape, dtype = float, order = 'C') |
参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | ‘C’ 用于 C 的行数组,或者 ‘F’ 用于 FORTRAN 的列数组 |
实例
1 | import numpy as np |
输出结果为:
1 | [0. 0. 0. 0. 0.] |
3.numpy.ones
和上面一样,0换成1,不再赘述
4.numpy.zeros_like
numpy.zeros_like 用于创建一个与给定数组具有相同形状的数组,数组元素以 0 来填充。
1 | import numpy as np |
输出结果为
1 | [[0 0 0] |
5.numpy.ones_like
numpy.zeros_like 用于创建一个与给定数组具有相同形状的数组,数组元素以 1 来填充。
4.切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
slice切割(了解即可,不推荐)
1 | import numpy as np |
冒号分隔切片(推荐,和前面学的list相通)
1 | import numpy as np |
上面我们演示的是单维数组,多维数组也是同理
1 | import numpy as np |
省略号切片
切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
1 | import numpy as np |
输出结果为
1 | [2 4 5] |
高级索引
NumPy 比一般的 Python 序列提供更多的索引方式。
除了之前看到的用整数和切片的索引外,数组可以由整数数组索引、布尔索引及花式索引。
整数数组索引
整数数组索引是指使用一个数组来访问另一个数组的元素。这个数组中的每个元素都是目标数组中某个维度上的索引值。以下实例获取数组中 (0,0),(1,1) 和 (2,0) 位置处的元素。
1 | import numpy as np |
输出结果为
1 | [1 4 5] |
整数数组索引还可以和切片:或……结合
已知我们如果想获得坐标(1,2)的元素可以这么写
1 | import numpy as np |
同样我们可以把逗号分隔的两个参数用切片改一下
1 | import numpy as np |
这样输出的就是一到二行的一到二列
布尔索引
还可以通过布尔索引来进行筛选,布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
1 | import numpy as np |
输出结果为:
1 | 我们的数组是: |
还可以使用~(取补运算符)来过滤
以下实例使用了 ~(取补运算符)来过滤 NaN。
1 | import numpy as np |
输出结果为:
1 | [ 1. 2. 3. 4. 5.] |
以下实例演示如何从数组中过滤掉非复数元素。
1 | import numpy as np |
输出如下:
1 | [2.0+6.j 3.5+5.j] |
花式索引
花式索引根据索引数组的值作为目标数组的某个轴的下标进行索引
对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素,如果目标是二维数组,那么就是对应下标的行。
花式索引跟切片不一样,它总是将数据复制到新数组中。
对于一维数组
1 | import numpy as np |
NumPy 广播(Broadcast)
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
1 | import numpy as np |
当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。如:
1 | import numpy as np |
NumPy迭代数组
1.nditer的迭代顺序
NumPy 迭代器对象 numpy.nditer 提供了一种灵活访问一个或者多个数组元素的方式。
1 | import numpy as np |
1 | 原始数组是: |
以上实例不是使用标准 C 或者 Fortran 顺序,默认是行序优先
这反映了默认情况下只需访问每个元素,而无需考虑其特定顺序。我们可以通过迭代上述数组的转置来看到这一点,并与以 C 顺序访问数组转置的 copy 方式做对比,如下实例:
1 | import numpy as np |
1 | 0, 1, 2, 3, 4, 5, |
第一个循环:np.nditer(a.T)
默认情况下,nditer会按照数组在内存中的存储顺序进行迭代。NumPy数组默认以行优先(‘C’风格)顺序存储。
关键点:a.T是转置视图(view),不是副本(copy),它保持了原始数组的内存布局。虽然逻辑上是3x2,但物理存储仍然是原始2x3数组的顺序。
因此,迭代a.T时实际是按照原始数组的内存顺序访问元素
第二个循环:np.nditer(a.T.copy(order='C'))
这里显式创建了一个C顺序的副本。order='C'指定了行优先存储。
副本会按照转置后的逻辑形状(3x2)和指定的C顺序重新排列内存中的元素,所以迭代顺序就是转置后的行优先顺序:
2.nditer的flags参数
nditer 类的构造器拥有 flags 参数,它可以接受下列值:
| 参数 | 描述 |
|---|---|
c_index |
可以跟踪 C 顺序的索引 |
f_index |
可以跟踪 Fortran 顺序的索引 |
multi_index |
每次迭代可以跟踪一种索引类型 |
external_loop |
给出的值是具有多个值的一维数组,而不是零维数组 |
在下面的实例中,迭代器遍历对应于每列,并组合为一维数组。
1 | import numpy as np |
1 | 原始数组是: |
3.nditer修改数组中元素的值
nditer 对象有另一个可选参数 op_flags。 默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值的修改,必须指定 readwrite 或者 writeonly 的模式。
1 | import numpy as np |
1 | 原始数组是: |
4.广播迭代
如果两个数组是可广播的,nditer 组合对象能够同时迭代它们。 假设数组 a 的维度为 3X4,数组 b 的维度为 1X4 ,则使用以下迭代器
1 | import numpy as np |
1 | 第一个数组为: |
NumPy 数组操作常用知识点
1. 修改数组形状
1.1 reshape
在不改变数据的情况下修改数组形状
1 | import numpy as np |
1.2 flatten 和 ravel
- flatten:返回数组的拷贝,修改不影响原始数组
- ravel:返回数组视图,修改会影响原始数组
1 | a = np.arange(8).reshape(2,4) |
2. 翻转数组
2.1 transpose 和 T
转置数组(行列互换)
1 | a = np.arange(12).reshape(3,4) |
3. 修改数组维度
3.1 expand_dims
扩展数组形状,在指定位置插入新轴
1 | x = np.array([[1,2],[3,4]]) |
3.2 squeeze
从数组形状中删除一维条目
1 | x = np.arange(9).reshape(1,3,3) |
4. 连接数组
4.1 concatenate
沿指定轴连接数组
注意:垂直堆叠要求垂直方向两个数组有对应的数字,若如下图则报错


1 | a = np.array([[1,2],[3,4]]) |
4.2 stack
沿新轴连接数组序列
1 | print(np.stack((a,b),0)) # 沿新轴0堆叠 |
4.3 hstack 和 vstack
- hstack:水平堆叠(按列)
- vstack:垂直堆叠(按行)
1 | print(np.hstack((a,b))) # 水平堆叠 |
5. 分割数组
5.1 split
将数组分割为多个子数组
1 | a = np.arange(9) |
5.2 hsplit 和 vsplit
- hsplit:水平分割(按列)
- vsplit:垂直分割(按行)
1 | a = np.arange(16).reshape(4,4) |
6. 数组元素的添加与删除
6.1 append
在数组末尾添加值
1 | a = np.array([[1,2,3],[4,5,6]]) |
6.2 insert
在指定位置插入值
1 | a = np.array([[1,2],[3,4],[5,6]]) |
6.3 delete
删除指定子数组
1 | a = np.arange(12).reshape(3,4) |
6.4 unique
去除数组中的重复元素
1 | a = np.array([5,2,6,2,7,5,6,8,2,9]) |
NumPy 排序与条件筛选常用函数
1. 排序函数
1.1 numpy.sort()
返回输入数组的排序副本
1 | import numpy as np |
1.2 numpy.argsort()
返回数组值从小到大的索引值
1 | x = np.array([3, 1, 2]) |
2. 最值索引函数
2.1 numpy.argmax() 和 numpy.argmin()
返回最大/最小元素的索引
1 | arr = np.array([[30, 40, 70], |
3. 条件筛选函数
3.1 numpy.where()
返回满足条件的元素索引
1 | # 创建示例数组 |
3.2 numpy.nonzero()
返回非零元素的索引
1 | arr = np.array([[0, 1, 0], |
3.3 numpy.extract()
根据条件从数组中抽取元素
1 | arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]) |
4. 实用排序技巧
4.1 按指定字段排序(结构化数组)
1 | # 创建结构化数组 |
4.2 分区排序 numpy.partition()
快速找到前k个最小/最大值
1 | arr = np.array([46, 57, 23, 39, 1, 10, 0, 120]) |
5. 实际应用示例
5.1 数据清洗:处理异常值
1 | # 生成包含异常值的测试数据 |
5.2 成绩排名系统
1 | # 学生成绩数据 |
这些函数是NumPy数据处理中最常用的工具,掌握它们能极大提高数据分析和处理的效率。