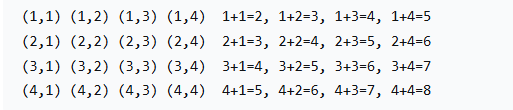参数 : 前u个数 选 or 不选 的
需要保存第x位置的状态的时候就需要用st数组来存状态 int st[] 0:没有遇见 1 选 2不选
代码模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int N = 16 ;int st[N]; int n;void dfs (int u) if (u > n) { for (int i = 1 ; i <=n; i ++ ){ if (st[i] == 1 ) { cout << i << ' ' ; } } puts ("" ); return ; } st [u] = 1 ; dfs (u + 1 ); st[u] = 0 ; st[u] = 2 ; dfs (u+1 ); st[u] = 0 ; } int main () cin >> n; dfs (1 ); return 0 ; }
P2089 烤鸡 - 洛谷
10 种配料,每种可以放 1~3 克 ,总美味程度 = 所有配料质量之和 = n,输出所有可能的配方数和配方(按字典序)没有方案则输出 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <bits/stdc++.h> using namespace std;int n;int a[11 ]; int cnt = 0 ;int m[60000 ][11 ]; void dfs (int x, int sum) if (sum > n) return ; if (x > 10 ) { if (sum == n) { cnt++; for (int i = 1 ; i <= 10 ; i++) { m[cnt][i] = a[i]; } } return ; } for (int i = 1 ; i <= 3 ; i++) { a[x] = i; dfs (x + 1 , sum + i); a[x] = 0 ; } } int main () ios_base::sync_with_stdio (false ); cin.tie (NULL ); cout.tie (NULL ); cin >> n; dfs (1 , 0 ); cout << cnt << endl; for (int i = 1 ; i <= cnt; i++) { for (int j = 1 ; j <= 10 ; j++) { cout << m[i][j] << " " ; } cout << endl; } return 0 ; }
[P2036 COCI 2008/2009 #2] PERKET - 洛谷
你有 n 种配料,每种可以选 或不选 ,但不能全不选。
总酸度 = 选中配料的酸度的乘积
总苦度 = 选中配料的苦度的总和
目标是 min(|酸度 - 苦度|)
由于每个调料可选可不选,我们可以用一个st数组判断状态,1表示选,2表示不选。最后计算的时候遍历数组,只有st[i]==1时才计算s,b。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> using namespace std;int n;int s, b;int st[200 ];int res = 1e9 ;struct node { int s, b; } a[20 ]; void dfs (int x) bool has= false ; if (x > n) { int sum1 = 1 ; int sum2 = 0 ; for (int i = 1 ; i <= n; i++) { if (st[i] == 1 ) { has = true ; sum1 *= a[i].s; sum2 += a[i].b; } } if (has) { res = min (res, abs (sum1 - sum2)); } return ; } st[x] = 1 ; dfs (x + 1 ); st[x] = 0 ; st[x] = 2 ; dfs (x + 1 ); st[x] = 0 ; } int main () ios_base::sync_with_stdio (false ); cin.tie (NULL ); cout.tie (NULL ); cin >> n; for (int i = 1 ; i <= n;i++){ cin >>a[i].s >> a[i].b; } dfs (1 ); cout << res << endl; return 0 ; }
当然还有一种写法。直接多往dfs里面传参
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;int n;int s[15 ], b[15 ];int ans = 1e9 ;void dfs (int index, int total_s, int total_b, bool chosen) if (index == n) { if (chosen) { ans = min (ans, abs (total_s - total_b)); } return ; } dfs (index + 1 , total_s, total_b, chosen); dfs (index + 1 , total_s * s[index], total_b + b[index], true ); } int main () cin >> n; for (int i = 0 ; i < n; i++) { cin >> s[i] >> b[i]; } dfs (0 , 1 , 0 , false ); cout << ans << endl; return 0 ; }
大概是每个位置要选什么数字,模板如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> using namespace std;const int N = 10 ;int path[N];int state[N];int n;void dfs (int u) if (u > n) { for (int i = 1 ; i <= n; i++) cout << path[i] << " " ; cout << endl; } for (int i = 1 ; i <= n; i++) { if (!state[i]) { path[u] = i; state[i] = 1 ; dfs (u + 1 ); state[i] = 0 ; } } } int main () cin >> n; dfs (1 ); }
先来一道模板题
P1706 全排列问题 - 洛谷
按照字典序输出自然数 1 到 n 所有不重复的排列,即 n 的全排列,要求所产生的任一数字序列中不允许出现重复的数字。
好像没什么好说的,太模板了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;int n;int a[100 ];bool vis[100 ];void dfs (int x) if (x > n) { for (int i = 1 ; i <= n; i++) { printf ("%5d" , a[i]); } printf ("\n" ); return ; } for (int i = 1 ; i <= n; i++) { if (!vis[i]) { a[x] = i; vis[i] = true ; dfs (x + 1 ); vis[i] = false ; } } } int main () cin >> n; dfs (1 ); return 0 ; }
[P1088 NOIP 2004 普及组] 火星人 - 洛谷
由1-n(不重复)组成的全排列数里,有a,b,假设全排列数列已经sort好,你要找到中找到a后面的第b个数。
这道题的本质就是全排列,如果不考虑数据范围的话,直接这么写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <bits/stdc++.h> using namespace std;int n, m;vector<vector<int >> all; vector<int > cur; bool vis[100 ];void dfs (int x, vector<int >& temp) if (x > n) { all.push_back (temp); return ; } for (int i = 1 ; i <= n; i++) { if (!vis[i]) { vis[i] = true ; temp[x-1 ] = i; dfs (x + 1 , temp); vis[i] = false ; } } } int main () ios_base::sync_with_stdio (false ); cin.tie (NULL ); cout.tie (NULL ); cin >> n >> m; cur.resize (n); for (int i = 0 ; i < n; i++) { cin >> cur[i]; } vector<int > temp (n) ; dfs (1 , temp); sort (all.begin (), all.end ()); int pos = -1 ; for (int i = 0 ; i < all.size (); i++) { if (all[i] == cur) { pos = i; break ; } } vector<int > result = all[pos + m]; for (int i = 0 ; i < n; i++) { cout << result[i]; if (i < n - 1 ) cout << " " ; } cout << endl; return 0 ; }
注意到题目N<10000,那枚举会达到恐怖的10000!。所以这段代码你交上去只能得20分。其他的MLE了。
剪枝好像也没有什么操作空间。
这时候不得不提到STL的喵喵小工具。
我们可以利用 C++ STL 的 next_permutation 函数来高效解决。
next_permutation 工作原理
从右向左找到第一个升序对 (i, i+1),满足 a[i] < a[i+1]
从右向左找到第一个大于 a[i] 的元素 a[j]
交换 a[i] 和 a[j]
将 a[i+1] 到末尾的元素反转
每次 next_permutation 操作:O(N)
总共 M 次操作:O(N × M)
在 N≤10000, M≤100 时完全可行
1 2 3 4 5 6 7 8 9 10 vector<int > fingers (n) ;for (int i = 0 ; i < n; i++) { cin >> fingers[i]; } for (int i = 0 ; i < m; i++) { next_permutation (fingers.begin (), fingers.end ()); }
就是如此简单,附上AC代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <bits/stdc++.h> using namespace std;int main () int n, m; cin >> n >> m; vector<int > fingers (n) ; for (int i = 0 ; i < n; i++) { cin >> fingers[i]; } for (int i = 0 ; i < m; i++) { next_permutation (fingers.begin (), fingers.end ()); } for (int i = 0 ; i < n; i++) { cout << fingers[i]; if (i < n - 1 ) cout << " " ; } cout << endl; return 0 ; }
与全排列的差别就是第二个for循环开始的位置,换句话说就是每个数该放什么位置。
模板如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <bits/stdc++.h> using namespace std;const int N = 30 ;int path[N];int n, m;void dfs (int u, int start ) if (u > m) { for (int i = 1 ; i <= m; i ++ ) { cout << path[i] << ' ' ; } puts ("" ); } else { for (int i = start; i <= n; i ++) { path[u] = i; dfs (u + 1 , i + 1 ); path[u] = 0 ; } } } int main () cin >> n >> m; dfs (1 ,1 ); return 0 ; }
[P1036 NOIP 2002 普及组] 选数 - 洛谷
已知 n 个整数 x 1,x 2,⋯,x**n ,以及 1 个整数 k (k <n )。从 n 个整数中任选 k 个整数相加,可分别得到一系列的和。求和为素数的有多少种
对于这个dfs的状态,三点就可以描述
idx:知道处理到哪了cnt:知道选了几个sum:知道当前和是多少
对于每个位置idx,有选和不选两种选择,如果选择
1 dfs (idx + 1 , cnt + 1 , sum + a[idx]);
如果不选
写dfs除了状态参数,第一个写的就是终止状态,什么时候终止呢,idx>n时说明已经考虑完所有数字了。但是此时还必须刚好选择k个元素,然后还要检查和是否为素数
1 2 3 4 5 6 if (idx > n) { if (cnt == k && is_prime (sum)) { ans++; } return ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <bits/stdc++.h> using namespace std;int n, k;int a[25 ];int ans = 0 ;bool is_prime (int x) if (x < 2 ) return false ; for (int i = 2 ; i * i <= x; i++) { if (x % i == 0 ) return false ; } return true ; } void dfs (int idx, int cnt, int sum) if (idx > n) { if (cnt == k && is_prime (sum)) { ans++; } return ; } if (cnt < k) { dfs (idx + 1 , cnt + 1 , sum + a[idx]); } dfs (idx + 1 , cnt, sum); } int main () cin >> n >> k; for (int i = 1 ; i <= n; i++) { cin >> a[i]; } dfs (1 , 0 , 0 ); cout << ans; return 0 ; }
P1135 奇怪的电梯 - 洛谷
有一栋 N 层的大楼,每层楼有一个数字 K_i,电梯有四个按钮:开、关、上、下。按”上”会移动到 当前楼层 + K_当前楼层,按”下”会移动到 当前楼层 - K_当前楼层。要求从 A 楼到达 B 楼,求最少需要按几次按钮,如果无法到达则输出 -1。
这是一个典型的最短路径搜索问题。我们可以把每个楼层看作图中的一个节点,每个合法的上下移动看作图中的边,问题就转化为了从节点 A 到节点 B 的最短路径问题。仍然是思考,状态表示,搜索过程,终止条件,以及回溯。
DFS 的设计思路:
状态表示 :(当前楼层, 已按按钮次数)搜索过程 :从起点 A 开始,每次尝试向上或向下移动终止条件 :到达目标楼层 B回溯机制 :尝试完一个方向后要取消标记,以便探索其他路径
至于题目提到的有时按钮超过上下限就会失灵的情况,我们只需要每次递归前判断一次一次即可。因为我们知道当前楼层,也就知道当前楼层要移动的距离k[h]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void dfs (int h, int cnt) if (cnt >= min1) return ; if (h == b){ min1 = min (min1, cnt); return ; } vis[h] = true ; int up = h + k[h]; if (up <= n && !vis[up]) { dfs (up, cnt + 1 ); } int down = h - k[h]; if (down >= 1 && !vis[down]) { dfs (down, cnt + 1 ); } vis[h] = false ; }
如果你这么写那就喜提超时了。我们继续思考剪枝优化,我们最开始的剪枝,是遍历到超过所有的最小方案数再剪枝。要进一步优化的话,就每到一层剪一次枝。我们用一个数组记录到达当前楼层的最小方案数。如果回溯过程中超过了,直接return。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <bits/stdc++.h> using namespace std;int n,a,b;bool vis[210 ];int min1 = 1e9 ;int k[210 ];int dist[210 ]; void dfs (int h, int cnt) if (cnt >= min1) return ; if (cnt >= dist[h]) return ; dist[h] = cnt; if (h == b){ min1 = min (min1, cnt); return ; } vis[h] = true ; int up = h + k[h]; if (up <= n && !vis[up]) { dfs (up, cnt + 1 ); } int down = h - k[h]; if (down >= 1 && !vis[down]) { dfs (down, cnt + 1 ); } vis[h] = false ; } int main () ios_base::sync_with_stdio (false ); cin.tie (NULL ); cout.tie (NULL ); cin >> n >> a >> b; for (int i = 1 ; i <= n; i++) { cin >> k[i]; dist[i] = 1e9 ; } dfs (a, 0 ); if (min1 == 1e9 ) cout << -1 ; else cout << min1; return 0 ; }
其实这道题还可以bfs,后面再补吧。
P2404 自然数的拆分问题 - 洛谷
现在给你一个自然数 n ,要求你求出 n 的拆分成一些数字的和。每个拆分后的序列中的数字从小到大排序。字典序小的优先输出
关于dfs的构建,我们需要三个关键状态:
当前序列 (vector<int> v):记录已经选择的数字当前和 (int sum):已选数字的总和起始数字 (int start):下一个数字的最小值(保证递增和字典序)
从数字 1 开始 ,这是最小的可能数字对于每个数字 i ,尝试将其加入当前序列递归搜索 :以 i 作为新的起始数字(保证后续数字 ≥ 当前数字)回溯 :撤销当前选择,尝试其他可能性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <bits/stdc++.h> using namespace std;int n;vector<int > v; void dfs (int start, int sum) if (sum == n) { if (v.size () == 1 ) { return ; } for (int i = 0 ; i < v.size (); i++) { cout << v[i]; if (i < v.size () - 1 ) cout << "+" ; } cout << endl; return ; } for (int i = start; i <= n - sum; i++) { if (sum + i <= n) { v.push_back (i); dfs (i, sum + i); v.pop_back (); } } } int main () ios_base::sync_with_stdio (false ); cin.tie (NULL ); cout.tie (NULL ); cin >> n; dfs (1 , 0 ); return 0 ; }
洛谷USACO1.5八皇后
nxn的棋盘,同一行和同一列不可以有两个棋子,且每条对角线都至多有一个棋子。让你给出三种解法里面的列标,以及最后的解法数。
非常典型的dfs回溯问题。唯一需要思考的,是我该怎么回溯。怎么来构建这个dfs图。
很朴素经典的dfs思想是,从第一行开始放棋,对于每一行,尝试完所有的位置,尝试完后到下一行。检查每个位置是否满足条件,满足就标记且占用,而且递归处理下一行。(记得要回溯尝试其他可能,要取消标记和占用)那么行数其实就是这个dfs树的深度(dep)了。你的脑子里应该马上有这一段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void dfs (int dep) if (dep==n+1 ){ } for (int i=1 ;i<=n;i++){ if (check){ dfs (dep+1 ) } } }
接下来就是完善细节。由于我们是一行一行遍历,找到符合条件的进入下一行**,所以完全不用担心一行会出现两**个棋子。所以我们需要考虑的只有对角线和每一列。注意我们还要标记每行里面放皇后的列号。因此我们需要两个数组来存储。vis数组看每列是否有访问,col数组存储每行放置棋子的列号。
对于对角线,如果你第一次接触这个问题可能会想到用循环解决,事实上有着更简单的检查方法。
对于主对角线 ,我们不难发现,行-列一定是一个同样的数字。
对于副对角线 ,我们也可以发现,列+行也是一个同样的数字
举个例子,如果我在(2,4)放了棋子
但是涉及到减号我们就要格外注意数组越界 ,因为行-列并不总是正数。
这里我们不需要边界检查,只需要用到一个常用的偏移技巧就好。都加上n。(不细说了自行脑补)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <bits/stdc++.h> using namespace std;const int N = 20 ;int n, total = 0 ;int col[N]; bool vis[N]; bool diag1[2 *N]; bool diag2[2 *N]; void print () for (int i = 1 ; i <= n; i++) { cout << col[i]; if (i < n) cout << " " ; } cout << endl; } void dfs (int dep) if (dep == n + 1 ) { total++; if (total <= 3 ) { print (); } return ; } for (int i = 1 ; i <= n; i++) { if (!vis[i] && !diag1[dep - i + n] && !diag2[dep + i]) { col[dep] = i; vis[i] = true ; diag1[dep - i + n] = true ; diag2[dep + i] = true ; dfs (dep + 1 ); vis[i] = false ; diag1[dep - i + n] = false ; diag2[dep + i] = false ; } } } void solve () cin >> n; dfs (1 ); cout << total << endl; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); solve (); return 0 ; }
洛谷P1019 [NOIP 2000 提高组] 单词接龙(疑似错题)
你有 n 个单词,每个单词最多用两次。给定一个起始字母,要找出最长的“龙”。接龙规则是相邻单词必须有重合部分,但不能是包含关系。
比如 beast 接 astonish,重合 "ast",变成 beastonish。
依旧典型的 DFS 回溯问题
依旧很朴素经典的 DFS 思想是:从起始字母的单词开始,对于当前龙字符串,尝试所有能接上的单词,接上后递归处理更长的龙,然后回溯尝试其他可能。
那么当前龙的长度 其实就是这个 DFS 树的深度。理清楚下dfs的要点
状态 :当前拼接的龙字符串 tmp选择 :所有使用次数 < 2 且能与当前龙末尾重合的单词递归深度 :龙的长度回溯 :恢复单词使用次数
这就是大概框架,接下来理一下细节
我们枚举重合长度。如果包含的话,会遍历到待接龙字符串的最后一位,所以我们不能取等。
1 for (int j = 1 ; j < min (tmp.size (), s[i].size ()); ++j)
匹配就是看当前字符的后面和待匹配字符的前面,用.substr()
tmp.substr(tmp.size() - j):取当前龙末尾 j 个字符s[i].substr(0, j):取候选单词开头 j 个字符两者相等说明可以接龙
1 tmp.substr (tmp.size () - j) == s[i].substr (0 , j)
去掉重合部分:当前龙 + 单词i去掉前j个字符
比如 "beast" 接 "astonish",重合 "ast":
"beast" + "astonish".substr(3) = "beast" + "onish" = "beastonish"
其实就是vis++,和一般的访问数组一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <bits/stdc++.h> using namespace std;string a[1000 ]; int n, ans; int vis[1000 ] = {0 }; string s; void dfs (const string& tmp) ans = max (ans, int (tmp.size ())); for (int i = 1 ; i <= n; i++) { if (vis[i] >= 2 ) continue ; for (int j = 1 ; j < min (tmp.size (), a[i].size ()); j++) { if (tmp.substr (tmp.size () - j) == a[i].substr (0 , j)) { vis[i]++; dfs (tmp + a[i].substr (j)); vis[i]--; } } } } void solve () cin >> n; for (int i = 1 ; i <= n; i++) { cin >> a[i]; } char c; cin >> c; for (int i = 1 ; i <= n; i++) { if (a[i][0 ] == c) { vis[i]++; dfs (a[i]); vis[i]--; } } cout << ans; } int main () ios::sync_with_stdio (0 ), cin.tie (0 ), cout.tie (0 ); solve (); return 0 ; }
这一版本的代码非常简单直观,但是也有它的问题
重复计算 :相同的单词对会在不同DFS路径中反复检查重合无效尝试 :有些单词根本不可能接上,但每次都要枚举
由于要长度最长,所以只需找到最小重合,重合越少最后越长。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int overlap[N][N]; void preprocess () for (int i = 1 ; i <= n; i++) { for (int j = 1 ; j <= n; j++) { overlap[i][j] = 0 ; for (int k = 1 ; k < min (s[i].size (), s[j].size ()); k++) { if (s[i].substr (s[i].size () - k) == s[j].substr (0 , k)) { overlap[i][j] = k; break ; } } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void dfs (const string &tmp, int last) ans = max (ans, (int )tmp.size ()); for (int i = 1 ; i <= n; i++) { if (vis[i] >= 2 ) continue ; int k = overlap[last][i]; if (k > 0 ) { vis[i]++; dfs (tmp + s[i].substr (k), i); vis[i]--; } } }
完整代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <iostream> #include <string> #include <algorithm> using namespace std;const int N = 30 ;int n, vis[N], ans;string s[N]; char c;int overlap[N][N]; void preprocess () for (int i = 1 ; i <= n; i++) { for (int j = 1 ; j <= n; j++) { overlap[i][j] = 0 ; for (int k = 1 ; k < min (s[i].size (), s[j].size ()); k++) { if (s[i].substr (s[i].size () - k) == s[j].substr (0 , k)) { overlap[i][j] = k; break ; } } } } } void dfs (const string &tmp, int last) ans = max (ans, (int )tmp.size ()); for (int i = 1 ; i <= n; i++) { if (vis[i] >= 2 ) continue ; if (overlap[last][i] > 0 ) { vis[i]++; dfs (tmp + s[i].substr (overlap[last][i]), i); vis[i]--; } } } int main () cin.tie (nullptr ); ios::sync_with_stdio (false ); cin >> n; for (int i = 1 ; i <= n; i++) cin >> s[i]; cin >> c; preprocess (); for (int i = 1 ; i <= n; i++) { if (s[i][0 ] == c) { vis[i]++; dfs (s[i], i); vis[i]--; } } cout << ans << '\n' ; return 0 ; }
P5194 [USACO05DEC] Scales S
有一个单调不降的序列,给你一个上限,你需要在序列里选出数,让它们累加之后最接近(但是不超过)给定的上限。
直接暴力搜索其实很简单,每个砝码选或者不选。不选就下一个,选的话加上这个质量。然后一直递归。考虑完所有砝码后检查是否合法并更新答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> #include <algorithm> using namespace std;#define ll long long const int MAX_N = 1005 ;ll m[MAX_N]; ll sum; ll n, c; void dfs (int index, ll cur) if (index > n) { if (cur <= c) { sum = max (sum, cur); } return ; } if (cur > c) { return ; } dfs (index + 1 , cur + m[index]); dfs (index + 1 , cur); } int main () cin >> n >> c; for (int i = 1 ; i <= n; i++) { cin >> m[i]; } sum = 0 ; dfs (1 , 0 ); cout << sum << endl; return 0 ; }
如果你这么写了,喜提TLE。
如果用dfs想优化时间复杂度,我们通常会进行剪枝 ,显然我们已经剪枝过了。那没有办法优化了吗?还能怎样进行剪枝?
注意到题目给出,它给出的序列是单调不降的。那我们可以从最后也就是最大数开始遍历。就可以借助前缀和 能帮快速判断能否全取。总结一下
从后往前考虑 :从最后一个砝码开始(index = n)两个选择 :
选当前砝码:dfs(index-1, cur + m[index])
不选当前砝码:dfs(index-1, cur)
两个剪枝 :
超重剪枝:当前总质量 > 承重
全取剪枝:当前质量 + 剩余所有砝码 ≤ 承重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <bits/stdc++.h> using namespace std;#define ll long long const int MAX_N = 1005 ;ll m[MAX_N]; ll maxSum; ll pre[MAX_N]; ll n, c; void dfs (int index, ll cur) maxSum = max (maxSum, cur); if (index == 0 ) { return ; } if (cur > c){ return ; } if (cur + pre[index] <= c){ maxSum = max (maxSum, cur + pre[index]); return ; } if (cur + m[index] <= c){ dfs (index - 1 , cur + m[index]); } dfs (index - 1 , cur); } int main () cin >> n >> c; for (int i = 1 ; i <= n; i++) { cin >> m[i]; pre[i] = pre[i - 1 ] + m[i]; } maxSum = 0 ; dfs (n, 0 ); cout << maxSum << endl; return 0 ; }
洛谷P5440
给你一个八位数,这八位数中会有不确定的数字用‘-’表示,第 1∼4 位构成年,第 5∼6 位构成月,第 7∼8 位构成日,不足位数用 0 补足,同时,要求日期所代表的这一天真实存在,且年的范围为 1∼9999。要求由“日”组成的两位数,由“月+日”组成的四位数,由“年+月+日”组成的八位数均为质数 。
既然是dfs专题,那我们首先想到的就是dfs暴力填充。填充完后判断这个日期是不是一个合法日期。比如肯定不能出现13月或者2月30这种。当然闰年也得注意一下。又因为和质数有关,所以我们需要一个质数判断函数(这里用一下欧拉筛优化)。思路好像很清晰了。那怎么设置这个dfs呢。
要传给dfs的参数是什么,毫无疑问是已经确定好的数字位数d。当d==8时我们判断是否符合题意。当d!=8时,我们就要判断当前位是不是一个固定的数字。如果是的话直接过,dfs(n+1),如果不是的话对当前位尝试0-9依次填充。(记得回溯)
欧拉筛板子,没什么好说的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void Euler_prime () vis[0 ] = 1 ; vis[1 ] = 1 ; for (int i = 2 ; i <= N; i++) { if (!vis[i]) prime[x++] = i; for (int j = 0 ; j < x; j++) { if (i * prime[j] > N) break ; vis[i * prime[j]] = 1 ; if (i % prime[j] == 0 ) break ; } } }
判断闰年,也很基础
1 2 3 4 5 6 7 8 9 10 bool is_run (int y) if (y % 4 == 0 ) { if (y % 100 == 0 ) { if (y % 400 == 0 ) return true ; return false ; } return true ; } return false ; }
检查日期合法性,分成年月日分别判断合法性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 bool legal (int y, int m, int d) if (m > 12 || m == 0 || d == 0 || y == 0 ) return false ; if (m == 2 ) { if (is_run (y)) { if (d > 29 ) return false ; return true ; } else { if (d > 28 ) return false ; return true ; } } else { const int daynum[] = {0 ,31 ,28 ,31 ,30 ,31 ,30 ,31 ,31 ,30 ,31 ,30 ,31 }; if (d > daynum[m]) return false ; return true ; } }
还有一个比较关键的部分是,你如何存储这个输入,可以让你的遍历更新更方便。因为带特殊符号,所以我们最开始输入一定是字符串。又因为涉及到整数运算,所以我们还要标记一下可以替换的数位。我们用一个数组date来标记,如果date==-1,表示可以替换。不然的话date=s[i]-‘0’转换为数字。
关键的构建dfs,我们采用按位构建的方法。我们定义dfs(d)表示当前正在处理第d位(从0开始计数)。当d==8时,说明我们已经构建了一个完整的8位数,此时进行日期合法性和质数条件的检查。
在dfs过程中,我们维护一个全局变量num,表示当前构建的数字。对于每一位:
如果该位是确定的(date[d] != -1),我们直接将这个数字加到num中,然后递归处理下一位
如果该位是不确定的(date[d] == -1),我们就需要尝试0-9的所有可能
但是直接尝试0-9的所有组合会导致搜索空间很大,所以我们需要进行剪枝优化:
月份第一位剪枝 (d==4):月份的第一位只能是0或1,因为月份最大是12,所以当i==2时可以直接break,因为20几月不存在月份有效性剪枝 (d==5):当处理月份的第二位时:
如果月份第一位是0(date[4]==0),那么第二位不能是0,因为00月不存在
如果当前尝试的月份超过12,可以直接break
日期第一位剪枝 (d==6):日期的第一位最大只能是3,因为日期最大是31,所以当i==4时可以直接break
这些剪枝能显著减少搜索空间,让算法在合理时间内完成。
当构建完8位数后,我们将其分解为年、月、日三部分:
年 = num / 10000
月 = (num % 10000) / 100
日 = num % 100
然后检查:
日期是否合法(年份1-9999,月份1-12,日期符合当月天数)
日、月日、年月日三个数是否都是质数
如果都满足,就找到一个有效解,ans加1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 #include <bits/stdc++.h> using namespace std;#define ll long long const int N = 100000000 ;int vis[N + 10 ]; int prime[N + 10 ];int x = 0 ;int ans = 0 ;int date[10 ]; int num = 0 ; void Euler_prime () vis[0 ] = 1 ; vis[1 ] = 1 ; for (int i = 2 ; i <= N; i++) { if (!vis[i]) prime[x++] = i; for (int j = 0 ; j < x; j++) { if (i * prime[j] > N) break ; vis[i * prime[j]] = 1 ; if (i % prime[j] == 0 ) break ; } } } bool is_run (int y) if (y % 4 == 0 ) { if (y % 100 == 0 ) { if (y % 400 == 0 ) return true ; return false ; } return true ; } return false ; } bool legal (int y, int m, int d) if (m > 12 || m == 0 || d == 0 || y == 0 ) return false ; if (m == 2 ) { if (is_run (y)) { if (d > 29 ) return false ; return true ; } else { if (d > 28 ) return false ; return true ; } } else { const int daynum[] = {0 ,31 ,28 ,31 ,30 ,31 ,30 ,31 ,31 ,30 ,31 ,30 ,31 }; if (d > daynum[m]) return false ; return true ; } } void dfs (int d) if (d == 8 ) { int y = num / 10000 ; int m = (num % 10000 ) / 100 ; int day = num % 100 ; if (legal (y, m, day)) { if (!vis[day] && !vis[m * 100 + day] && !vis[y * 10000 + m * 100 + day]) { ans++; } } return ; } if (date[d] != -1 ) { num = num * 10 + date[d]; dfs (d + 1 ); num /= 10 ; return ; } for (int i = 0 ; i <= 9 ; i++) { if (d == 4 && i == 2 ) break ; if (d == 5 && i == 0 && date[4 ] == 0 ) continue ; if (d == 5 && date[4 ] * 10 + i > 12 ) break ; if (d == 6 && i == 4 ) break ; date[d] = i; num = num * 10 + i; dfs (d + 1 ); date[d] = -1 ; num /= 10 ; } } int main () ios::sync_with_stdio (false ); cin.tie (0 ); int t; cin >> t; Euler_prime (); while (t--) { ans = 0 ; num = 0 ; string s; cin >> s; for (int i = 0 ; i < 8 ; i++) { if (s[i] == '-' ) { date[i] = -1 ; } else { date[i] = s[i] - '0' ; } } dfs (0 ); cout << ans << endl; } return 0 ; }
看到题解的那一刻我是有点破防的。我对我写出的逻辑清晰的代码十分满意,但洋洋洒洒也有一百行以上了。题解是把预处理做到了极致。
采用预处理+模式匹配 的解法,核心思想是:
预先计算所有可能的奇迹日期 对每个查询,检查预处理日期是否匹配输入模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 #include <bits/stdc++.h> using namespace std;const int prime_days[] = {0 , 3 , 5 , 7 , 11 , 13 , 17 , 19 , 23 , 29 , 31 };const int month_days[] = {0 , 31 , 28 , 31 , 30 , 31 , 30 , 31 , 31 , 30 , 31 , 30 , 31 };vector<int > valid_dates; bool is_prime (int x) if (x < 2 ) return false ; for (int i = 2 ; i * i <= x; i++) if (x % i == 0 ) return false ; return true ; } bool is_leap_year (int year) return (year % 4 == 0 && year % 100 != 0 ) || (year % 400 == 0 ); } void preprocess () for (int month = 1 ; month <= 12 ; month++) { int max_day = month_days[month]; for (int j = 1 ; j <= 10 ; j++) { int day = prime_days[j]; if (day > max_day) continue ; int month_day = month * 100 + day; if (!is_prime (month_day)) continue ; if (!is_prime (day)) continue ; for (int year = 1 ; year <= 9999 ; year++) { if (month == 2 && day == 29 && !is_leap_year (year)) continue ; int full_date = year * 10000 + month_day; if (is_prime (full_date)) { valid_dates.push_back (full_date); } } } } } int main () ios::sync_with_stdio (false ); cin.tie (0 ); preprocess (); int T; cin >> T; while (T--) { string pattern; cin >> pattern; int count = 0 ; for (int date : valid_dates) { string date_str = to_string (date); while (date_str.length () < 8 ) { date_str = "0" + date_str; } bool match = true ; for (int i = 0 ; i < 8 ; i++) { if (pattern[i] != '-' && pattern[i] != date_str[i]) { match = false ; break ; } } if (match) count++; } cout << count << "\n" ; } return 0 ; }
P1378 油滴扩展 - 洛谷
在一个矩形框内给定 N 个点,我们可以按一定顺序在这些点上放置油滴。安排放置顺序 ,使所有油滴覆盖的总面积最大,从而矩形剩余面积最小。
人为什么能蠢成这样,半径应该是连续值 ,由几何条件决定,不是离散枚举。就这样写出了一段史山(划掉)
1 2 3 4 5 6 7 8 9 10 11 12 void mark (point p,int r) for (int i = p.x - r; i <= p.x + r; i++) { for (int j = p.y - r; j <= p.y + r; j++) { if (i >= 0 && i < n && j >= 0 && j < n) { if ((i - p.x) * (i - p.x) + (j - p.y) * (j - p.y) <= r * r) { a[i][j] = 1 ; } } } } }
言归正传。
对于当前要放置的油滴,它的最大半径由两个因素决定:
到矩形四边的距离
到已放置油滴的圆心距离减去该油滴的半径
半径公式:
text
1 r = min( dist_to_boundary, dist_to_other_circle_radius )
其中 dist_to_other_circle_radius 对于每个已放置油滴 j 是 dist(i, j) - r_j,如果小于 0 则半径取 0。
用 DFS 枚举所有排列顺序,计算每种顺序下的油滴总面积,取最大值。
状态 :当前已放置的油滴数量 cnt,当前油滴总面积 total_area选择 :所有未使用的油滴递归深度 :油滴数量 N回溯 :恢复油滴的使用状态和半径
矩形边界处理 x1 ≤ x2, y1 ≤ y2。半径计算 四舍五入输出 round() 处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <bits/stdc++.h> using namespace std;const double PI = acos (-1.0 );int n;double x, y, x2, y2;double max_oil = 0 ;bool vis[10 ];double r[10 ]; vector<pair<double , double >> points; double dist (double x, double y, double x2, double y2) return sqrt ((x - x2) * (x - x2) + (y - y2) * (y - y2)); } void dfs (int cnt, double total_area) if (cnt == n) { max_oil = max (max_oil, total_area); return ; } for (int i = 0 ; i < n; i++) { if (!vis[i]) { double max_r = 1e9 ; max_r = min (max_r, abs (points[i].first - x)); max_r = min (max_r, abs (points[i].first - x2)); max_r = min (max_r, abs (points[i].second - y)); max_r = min (max_r, abs (points[i].second - y2)); for (int j = 0 ; j < n; j++) { if (vis[j]) { double d = dist (points[i].first, points[i].second, points[j].first, points[j].second); max_r = min (max_r, d - r[j]); } } if (max_r < 0 ) max_r = 0 ; vis[i] = true ; r[i] = max_r; dfs (cnt + 1 , total_area + PI * r[i] * r[i]); vis[i] = false ; r[i] = 0 ; } } } int main () cin >> n; cin >> x >> y >> x2 >> y2; points.resize (n); for (int i = 0 ; i < n; i++) { cin >> points[i].first >> points[i].second; } if (x > x2) swap (x, x2); if (y > y2) swap (y, y2); double rect_area = (x2 - x) * (y2 - y); dfs (0 , 0.0 ); int ans = round (rect_area - max_oil); cout << ans << endl; return 0 ; }
P1123 取数游戏 - 洛谷
一个n*m的数组里面取数字,要求互不相邻(周围八个),求最多能取出几个。
这种二维的数组,我们是不方便遍历回溯的,因为我们需要变量稳定,一个不受另一个影响。所以就会用到一个常用的技巧,二维转一维。事实上我们只要规定从上往下从左到右开始数,知道是第几个就可以知道它的二维坐标。
1 2 int x = (pos-1 ) / m + 1 ; int y = (pos-1 ) % m + 1 ;
原理不细说,可以自己想想。那么我们dfs的构造就明细了。
状态 枚举到了第pos个数字,选了sum个数选择 对于这个数你可以选或不选
当然还有一个约束条件是不能相邻,那在外面写一个判断函数就好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #include <bits/stdc++.h> using namespace std;int n,m;int dx[]={-1 ,-1 ,0 ,1 ,1 ,1 ,0 ,-1 };int dy[]={0 ,1 ,1 ,1 ,0 ,-1 ,-1 ,-1 };int a[7 ][7 ];bool vis[7 ][7 ];int max1;bool check (int x,int y) for (int i=0 ;i<8 ;i++){ int nx=x+dx[i]; int ny=y+dy[i]; if (nx>=1 && nx<=n && ny>=1 && ny<=m && vis[nx][ny]){ return false ; } } return true ; } void dfs (int pos,int sum) if (pos>n*m){ max1=max (max1,sum); return ; } int x = (pos-1 ) / m + 1 ; int y = (pos-1 ) % m + 1 ; dfs (pos+1 ,sum); if (check (x,y)){ vis[x][y]=true ; dfs (pos+1 ,sum+a[x][y]); vis[x][y]=false ; } } int main () ios_base::sync_with_stdio (false ); cin.tie (NULL ); cout.tie (NULL ); int t; cin >> t; while (t--) { cin >> n >> m; for (int i = 1 ; i <= n; i++) { for (int j = 1 ; j <= m; j++) { cin >> a[i][j]; } } max1 = 0 ; memset (vis, false , sizeof (vis)); dfs (1 ,0 ); cout << max1 << endl; } return 0 ; }
其实到这你就能过了,但是这题还可以优化。也就是进行剪枝。
如果剩下的所有数字都加上也不如当前最优解,直接返回
1 2 3 4 5 6 7 int remaining = 0 ; for (int i = pos; i <= n*m; i++) { int rx = (i-1 ) / m + 1 ; int ry = (i-1 ) % m + 1 ; remaining += a[rx][ry]; } if (sum + remaining <= max1) return ;
[P3958 NOIP 2017 提高组] 奶酪 - 洛谷
我们需要判断老鼠能否通过奶酪中的空洞从下表面(z=0)到达上表面(z=h)。一个三维问题
题目说“如果两个空洞相切或是相交,则 Jerry 可以从其中一个空洞跑到另一个空洞,”
也就是说每个圆如果相切相交,就是可联通可到达的。能不能从下表面到上表面,其实就是一个寻找路径的问题。特别的,路径有不同的起点和终点。
起点要求,对应的圆要和下表面相切或者相交,终点要求,对应的圆要和上表面相切或者相交。这里我们可以用一个数组分别标记一下可以作为起点终点的圆。
那我们可以预处理一下,通过距离判断,从一个圆可以到哪个圆,到这里你有没有想到邻接矩阵?
开始建图!
将每个空洞看作图中的一个节点
如果两个空洞相交或相切,则在对应节点间建立无向边
如果空洞与下表面接触,将其加入起点集合
如果空洞与上表面接触,将其加入终点集合
空洞相交判断 :两空洞中心距离 ≤ 2r(即距离平方 ≤ 4r²)与表面接触判断 :
下表面:空洞底部 z ≤ r
上表面:空洞顶部 z ≥ h - r
读入所有空洞坐标
找出所有与上下表面接触的空洞
建立邻接矩阵表示空洞间的连通关系
对每对起点和终点进行DFS搜索
如果找到任意一条连通路径则输出”Yes”,否则输出”No”
参数设置:由于是寻找路径问题,我们令current为当前所在节点,target为目标节点
终止条件:当前节点等于目标节点时返回
遍历:遍历所有相邻结点,已经走过的用vis标记
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 #include <bits/stdc++.h> using namespace std;int n, h, r; bool flag; bool adj[1005 ][1005 ]; bool vis[1005 ]; struct point { int x, y, z; } a[1005 ]; vector<int > down; vector<int > up; void dfs (int cur, int target) if (cur == target) { flag = true ; return ; } vis[cur] = true ; for (int i = 1 ; i <= n; i++) { if (adj[cur][i] && !vis[i]) { dfs (i, target); } } } int main () ios_base::sync_with_stdio (false ); cin.tie (NULL ); cout.tie (NULL ); int t; cin >> t; while (t--) { flag = false ; memset (adj, false , sizeof (adj)); down.clear (); up.clear (); cin >> n >> h >> r; for (int i = 1 ; i <= n; i++) { cin >> a[i].x >> a[i].y >> a[i].z; if (a[i].z <= r) { down.push_back (i); } if (a[i].z >= h - r) { up.push_back (i); } } for (int i = 1 ; i <= n; i++) { for (int j = i + 1 ; j <= n; j++) { long long dist_sq = (long long )(a[i].x - a[j].x) * (a[i].x - a[j].x) + (long long )(a[i].y - a[j].y) * (a[i].y - a[j].y) + (long long )(a[i].z - a[j].z) * (a[i].z - a[j].z); long long r_sq = (long long )4 * r * r; if (dist_sq <= r_sq) { adj[i][j] = true ; adj[j][i] = true ; } } } for (int i = 0 ; i < down.size () && !flag; i++) { for (int j = 0 ; j < up.size () && !flag; j++) { memset (vis, false , sizeof (vis)); dfs (down[i], up[j]); } } if (flag) { cout << "Yes" << endl; } else { cout << "No" << endl; } } return 0 ; }
其实这道题还有并查集写法,但是普通的并查集会超时,这里只做示范用,代码过不了评测。
并查集是一种用于管理分组的高效数据结构,支持两种操作:
find(x):查找x所在的集合代表unite(x, y):合并x和y所在的集合
1 2 3 4 5 struct Point { long long x, y, z; }; vector<int > parent;
1 2 3 4 5 6 7 8 9 10 11 int find (int x) return parent[x] == x ? x : parent[x] = find (parent[x]); } void unite (int x, int y) x = find (x); y = find (y); if (x != y) parent[y] = x; }
1 2 3 parent.resize (n + 2 ); for (int i = 0 ; i <= n + 1 ; i++) parent[i] = i;
1 2 3 4 5 6 7 8 9 for (int i = 1 ; i <= n; i++) { cin >> points[i].x >> points[i].y >> points[i].z; if (points[i].z <= r) unite (0 , i); if (points[i].z >= h - r) unite (n + 1 , i); }
1 2 3 4 5 6 7 8 9 10 11 for (int i = 1 ; i <= n; i++) { for (int j = i + 1 ; j <= n; j++) { long long dx = points[i].x - points[j].x; long long dy = points[i].y - points[j].y; long long dz = points[i].z - points[j].z; if (dx*dx + dy*dy + dz*dz <= 4LL * r * r) { unite (i, j); } } }
1 2 3 4 5 if (find (0 ) == find (n + 1 )) { cout << "Yes" << endl; } else { cout << "No" << endl; }